5 Indexing
5.1 Example microblog search application
예제 앱으로 마이크로 블로그를 만들어서 인덱스를 달아보자
- 5.1.1 Representing content for searching
data schema
id : 1
screen_name :@thelabdude
type : post
timestamp : 2012-01-01T09:30:22Z
lang: en
user_id : 123
favorites_count : 10
text: #Yummm :) Drinking a latte at Caffé Grecco in SF’s historic North Beach. Learning text analysis with #SolrInAction by @ManningBooks on my iPad
- screen_name, type, timestampe, lang,text 등을 인덱스에 추가하는게 좋다. 예를 들어 아래와 같은 쿼리를 생각해보면
- 특정유저(screen_name:thelabdude)가 영어로(lang:en) 특정일이후(timestamp)를 검색할 가능성이 높다.
- 5.1.2 Overview of the Solr Indexing process
- 다큐먼트를 솔라가 지원하는 포멧으로 변경(xml or json….etc)
- 다큐먼트를 솔라에 추가(http post 등 사용)
- 솔라 다큐먼트를 인덱싱할때 사용할 텍스트 분석 방법 등을 설정
5.2 Designing your schema
서치엔진 디자인 방법을 배우자 이섹션 이후에 아래의 질문에 답할수 있다.
- 인덱스된 문서는 무었인가?
- 문서는 어떻게 유니크하게 구분할수 있는가.
- 어떤 필드가 유저의 서치에 사용되는가?
- 어떤 필드가 서치 결과에 디스플레이 되는가?
5.2.1 Document granularity
솔라 인덱스에 문서가 어떻게 표현될것인가?
책의 경우 책으로 인덱싱해야 하는가? 아니면 서브 섹션으로 인덱싱 해야 하는가?(ex 챕터단위)
- 텍스트 분석을 검색한다고 할때 인덱스 단위를 책으로 하면 책이름이 결과에 나온다.
- 하지만 챕터 단위로 인덱싱을 하면 너무 많은 챕터가 결과에 나오게 된다.
- 5.2.2 Unique key
- 솔라에서 유니크 키를 요구하지 않지만 줄경우
- 같은 키가 두번 들어오면 이전 문서를 overwrite 한다.
- 5.2.3 Indexed fields
5.2.4 Stored fields
검색에 사용하지는 않지만 결과에 보여주기 위해서 추가하는 필드
5.2.5 Preview of schema.xml
conf/sechma.xml
- <field>,<dynamicField> 기본 필드 정의
- <uniqueKey>,<copyField>,<fields>
- <types> 자료형 관련
5.3 Defining fields in schema.xml
> invert search index를 만들기 위해 해당 필드에 어떤 분석이 필요한지 정의
```xml
<field name="id" type="string" indexed="true" stored="true" required="true" />
```
- name 이름
- type 다루어지는 타입
- indexed 인덱스 여부(인덱스 되면 해당 필드가 조각조각 분리되서 인덱스됨 원본이 저장 안됨으로 결과에 필요할 경우 리턴할수 없음)
- stored 저장 여부(원본이 저장)
- required 필수 여부
- 5.3.2 Multivalued fields
아래 처럼 설정 하게 되면 여러 값으로 구성된 필드를 인덱스 할수 있다.
<field name="link" type="string" indexed="true" stored="true" multiValued="true"/>
data:
<field name="link">http://manning.com/grainger/</field>
<field name="link">http://lucene.apache.org/solr/</field>
5.3.3 Dynamic fields
s_, _s 처럼 prefix or suffix 로 필드명을 선언하고 정의할수 있다. 위의 규칙에 해당되는 모든 필드가 잡인다.
- 많은 필드 등록해야 할때
- 여러 소스에서 문서가 올때
새로운 소스를 더해야 할때
필요할 경우 사용하면된다.Multivalued fields로도 사용가능
여러소스에서 문서가 올때 예를 들면 페이스북,트위터,구글+ 등에서 오면 기본적으로 공통적인 필드를 잡아주고 각각의 sns에 특화된 필드는 아래와 같은 방법으로 정의해서 사용할수있다.
schema.xml
<field name="*_f" type="string" indexed="true" stored="true" />
<field name="*_g" type="string" indexed="true" stored="true" />
<field name="*_t" type="string" indexed="true" stored="true" />
data
<field name="facebook1_f">hello</field>
<field name="facebook2_f">world</field>
<field name="twitter1_t">foo</field>
<field name="twitter2_t">bar</field>
새로운 소스에 추가할때 예를 들어 add_s라는 새로운 속성이 생겨도 schema.xml 을 변경하지 않고 추가 할 수 있다.
schema.xml
<field name="*_s" type="string" indexed="true" stored="true" />
data
<field name="add_s">hello</field>
하지만 쿼리를 던질때는 필드명을 명시해 주어야한다.
5.3.4 Copy fields
- 여러필드의 내용을 종합해 하나의 필드를 만들고 해당 필드에 검색을 할수 있게 해줌
- 동일 필드에 다른 종류의 분석이 필요할때 사용
Create a catch-all field from many fields
구글을 보면 단하나의 서치 박스만 존재한다. 하지만 우리는 해당 박스에서 유저 이름도, 내용도 모두 검색되기를 바란다. 이럴때 사용하는게 여러 필드를 하나로 합쳐서 쿼리가 검색되게 할수있다.
<schema>
<fields>
<field name="catch_all" type="text_en" indexed="true" stored="false" multiValued="true"/>
</fields>
<copyField source="screen_name" dest="catch_all" />
<copyField source="text" dest="catch_all" />
<copyField source="link" dest="catch_all" />
<types>
</types>
</schema>
- stored는 꼭 false 로 하자 보여줄 필요는 없으니까
- 합쳐져야 하는 필드중 단 하나라도 multiValue가 있으면 multiValued=true 로 해야 된다.
- source 와 dest field 두개다 field 에 선언되어 았어야 한다.
Apply diffent analyzers to a field
예를 들어 하나의 필드에 stemming 을 한다고 해보자 하지만 stemming 을 하면 recall은 올라가겠지만 해당 필드에서 autosuggest도 지원한다고 하면 우리는
humanities 같은건 제시해 줄 수 없다. 그렇다면 어떻게 해야 할까? 복사해서 하면된다
<field name="text" type="stemmed_text" indexed="true" stored="true"/>
<field name="auto_suggest" type="unstemmed_text" indexed="true" stored="false" multiValued="true"/>
<copyField source="text" dest="auto_suggest" />
5.3.5 Unique key field
유니크 필드가 있으면 duplicate 관련 문제를 쉽게 처리할수 있다. 또한 솔라를 분산서버로 구성할려고 할때도 매우 유용하다
<uniqueKey>id</uniqueKey>
- primitive type을 쓰자(string, long 등) 커스톰 타입을 쓰면 오류가 발생 할 수 있다.
5.4 Field types for structrued nontext fields
여기서는 일단 구조화된 필드 타입을 다루고 6장에서는 textfield(unstructured)타입을 다루자
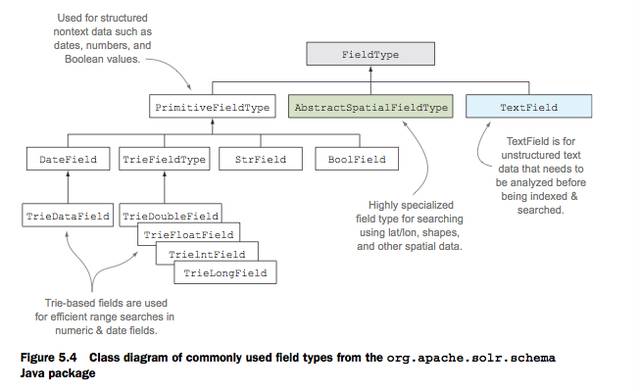
5.4.1 String fields
languagecode, screen_name(user_name) 등은 stirng 필드이다 솔라에서 string field는 이미 구조화되어 있는 필드를 말한다. language code 의 경우 이미
ko-KR,en-US 등으로 구조화 되어 있다.
<fieldType name="string" class="solr.StrField" sortMissingLast="true" omitNorms="true"/>
- solr.StrField 는 org.apache.solr.schema.StrField 로 바뀌어 해당 자바 클래스를 사용한다.
5.4.2 Date fields
날짜의 경우 유저가 범위검색을 할경우가 많다 솔라에서는 아래와 같이 검색이 가능하다. timestamp:[2012-05-01T00:00:00Z TO *]
<fieldType name="tdate" class="solr.TrieDateField" omitNorms="true" precisionStep="6" positionIncrementGap="0"/>
- trie 는 tree-based 자료구조를 의미한다.
- 범위 검색이 필요 없을 경우 아래와 같이 정의해도 된다.
<field name="timestamp" type="tdate" indexed="true" stored="true" />
- 솔라에서 기본적으로 DATE 는 ISO-8601 Date/Time format (yyyy-MM-ddTHH:mm:ssZ)를 따른다고 가정한다.
- 인덱싱을 할때 DATE granularity 를 조절 할수 있다.
- 만약 hour로 조절한다면 검색할때 분단위로는 검색할 없다.
- 아래는 인덱싱할때 시간으로 반내림해서 인덱스 하는 데이터의 예제이다.
<field name="timestamp">2012-05-22T09:30:22Z/HOUR</field>
- 아래와 같은 키워드를 사용해서 날짜 검색을 할수 있다. (NOW는 솔라 서버 기준시)
timestamp:[NOW/DAY TO NOW/DAY+1DAY}
5.4.3 Numeric fields
Numeric fields은 대부분 예상하는대로 돌아간다. 하지만 검색 결과를 sorting 할떄도 사용할수있다.
<field name="favorites_count" type="int" indexed="true" stored="true" />
<fieldType name="int" class="solr.TrieIntField" precisionStep="0" positionIncrementGap="0"/>
- precision step fast range querie에 사용되는대 위에서는 사용할 필요가 없음으로 0 으로 설정
- 타입이 string 일 경우 sorting 하면 lexical order로 솔팅한다.
5.4.4 Advanced field type attributes
5.5 sending documents to solr for indexing
인덱스 할때에 대해서 공부해보자
5.5.1 indexing documents using XML or JSON
//xml 인덱스예제
cd solr/example-docs
java -jar post.jsr ch5/tweet.xml
5.5.2 Using the SolrJ client library to add document from java
각 언어별로 라이블러리가 존재하며 어플리케이션에서 사용할때 해당 라이블러리를 사용하면좋다.
solrJ의 경우 내부적으로 로드 벨런싱과 배치잡등을 수행할수 있다.
5.5.3 Other tools for importing documents into Solr
5.6 Update handler
> 솔라에서 업데이트 핸들러가 처리하는 작업에 대해 공부해보자
- add : 문서를 인덱스에 추가
- delete: 문서를 인덱스에서 제거
- delete by query: 쿼리에 일치하는 문서 삭제
- Atomic updtae : 낙관적 락을 잡고 문서의 1개 또는 여러개의 필드를 변경하는것
- commit : 인덱스에 문서를 커밋하는것 (softCommit, or hardCommit)
- optimize : 조각난 세그먼트 합치고, 지워진 문서 삭제
5.6.1 Committing documents to the index
- 솔라는 soft,nomal(hard)두 종류의 커밋을 가지고 있다
- 커밋하기 전에는 서치 결과에 더해진 문서가 노출되지 않는다.
Nomal Commit
uncommit 상태인 모든 문서를 디스크에 적고 searcher 를 재생성한다.
커밋은 비싼 동작이다 왜냐하면 서처를 다시 만들어야 하기때문이다.
Soft Commit
near real time (NRT) searching 을 지원 하려고 추가되었다 하드 커밋에서 데이터를 디스크에 내리는 오퍼레이션을 제거 함으로 상대적으로 하드커밋에 비해 조금싸지만 서버 크래시시 데이터를 보장 못한다.
문서를 디스크에쓰고 새로운 서처를 만든다.(비싸다)
문서를 디스크에 쓰지 않고 문서를 검색될수 있게 만든다.(싸다)
Autocommit
- 특정시간에 커밋되게 할수 있다.(10시 00분)
- 특정 기준에 uncommited 문서가 닿으면 커밋되게 할수있다.
- 특정 간격 마다 실행되게 할수있다(매 10분)
<autoCommit>
<maxTime>600000</maxTime>
<maxDocs>50000</maxDocs>
<openSearcher>true</openSearcher>
</autoCommit>
위처럼 설정할수 있으며 openSearcher false 로 할 경우 서처를 새로 생성 하지 않는다.<autoSoftCommit>
<maxTime>1000</maxTime>
</autoSoftCommit>
위처럼 자동으로 소프트 커밋이 되게 할수도 있다.
5.6.2 Transction log
커밋하지 않으면 데이터가 날라가니 해당 사항을 보안하기 위해 로그를 남기자
- atomic 업데이트, 실시간 get 을 반영하기 위해 사용됨
- 데이터가 영속적으로 저장되는걸 보장하기 위해
SolrCloud에서 샤드 리더가 replication 들과 sync(동기)상태를 유지 하기 위해서
<updateLog>
<str name="dir">${solr.ulog.dir:}</str>
</updateLog>
커밋을 하기 전까지 트랜젝션 로그는 계속 늘어나다가 커밋을 하면 이전 트랜잭션 로그를 전부 처리한후 새로운 트랙잰션 로그 파일을 생성한다.
업데이트 핸들러 처리 순서
- 클라이언트에서 HTTP POST로 업데이트 요청
- 제티에서 요청을 받아 솔라로 라우팅
- 솔라에서 collection1 로 dispaching
- solrconfig.xml 에 설정된 /update 핸들러에서 처리
- 업데이트 프로세스 시작 schema.xml 의 설정에 따라 인덱스 업데이트
- 트렌젝션 로그에 add 요청을 적음
디스크에 로그가 적이면 리스판스에 성공을 리턴
@트랜잭션 로그가 커지면 커질수록 재시작이 느려진다. trade-off 를 생각해서 설정
5.6.3 Atomic updates
존재하는 특정 문서에 새로운 버전의 문서를 보내서 업데이트 할수있다. 하지만 우리가 생각하는 칼럼 업데이트가 아니라 전체 문서를 업데이트 하는 방식으로 동작한다.(예전 문서 삭제, 새로운 문서 등록)
- 문서의 필드 하나를 고치던 전체 필드를 고치던 전체 문서 업데이트를 한다.
- 예전에는 위와 같은 이유로 클라이언트에서 예전 문서를 받아서 필드를 수정하고 신규 문서의 모든 데이터를 다시 솔라로 보내면 솔라가 갱신하는 프로세스 였다.
- 하지만 업데이트 되면서 클라이언트에서는 특정 필드만 보내면된다. 물런 내부적으로는 삭제후 신규로 만든다.
schema.xml(이미 정의되어 있었음)
<dynamicField name="*_ti" type="tint" indexed="true" stored="true"/>
request 데이터
<add>
<doc>
<field name="id">1</field>
<field update="set" name="retweet_count_ti">100</field>
 </doc>
</add>
해당 필드가 문서에 추가되었을때 아래와 같이 하면 솔라는 해당 아이디를 찾아 모두 지우고 예전문서에 새로운 필드를 달아 문서를 등록한다.
Optimistic concurrrcnvy control
예를 들어 A라는 문서의 한 필드를 두명이 동시에 변경한다고 해보자 이럴 경우 락컨트롤이 필요하는대 솔라에서는 낙관적 락이라는 패턴을 사용한다.
- 해당 필드를 변경하려는 클라이언트는 서버에 http://주소:/solr/collection/get?id=1&fl=id,_version_ 해당 문서의 버전 정보를 요청한다. 그후 해당 문서의 버전과 변경되는 필드를 변경 후 서버로 업데이트 한다.
- get은 트랜잭션 로그를 사용하여 문서의 커밋 여부에 상관없이 현재 해당 문서의 마지막 버전 정보를 리턴하다.
- A 와 B가 동시에 같은 get을 요청해서 1을 받고 {A,1,val1},{B,1,val2}의 변경이 동시에 서버로 간다면
- 서버에는 해당 문서의 id 와 버전을 체크해서 버전이 일치해야만 변경후 선공을 돌려주고 버전이 다르면 실패를 리턴한다
- 위의 패턴을 사용할 경우 동시성 문제에 대해서 쉽게 처리 할수 있다.
- 위의 방식이 아니라 업데이트 요청히 version에 값을 줘서 처리하는 방법도 있다
version : solr behavior is
>1 Versions must match or the update fails.
1 The document must exist.
<0 The document must not exist.
0 No concurrency control desired, existing value is overwritten.
5.7 Index management
솔라 인덱스 세팅은 고급 유저를 위한거다 기본 사항을 변경하려면 확인 하고 변경하자
5.7.1 Index storage
솔라는 영속 저장소를 논리적으로 분리하기 위해 directory 라는 컴포넌트를 사용한다. 아래는 해당 디자인을 사용한 이점이다.
- 영속 저장소가 파일인지 DB인 상관없이 읽고 쓰기에만 집중가능
- 인덱스 corruption 을 막기 위해서 각각 영속저장소에서 제공하는 락기능 사용
- JVM & OS 의 특정한 특징에서 부터 solr 를 격리시킴
- NRT serach 같은 기능을 필요할 경우 상속받아 커스터 마이징 할 수 있음
여러 종류의 디렉토리 구현체를 가지고 있으나 모두 장단점이 있음 필요한곳에 적절이 써야함
Default Storage configuration
솔라는 기본적으로 로컬 파일 시스템을 디폴트 디렉티브로 사용함
ex) /example/solr/collection1/data/.
solrconfig.xml
<dataDir>${solr.data.dir:}</dataDir>
- 에서 설정되어 있으며 solr.xml 에서도 정의할수 있음
<core loadOnStartup="true" instanceDir="collection1/" transient="false" name="collection1" dataDir="/usr/local/solr-data/collection1"/>
- 권고 사항
- 각각의 코어는 다른 프로세스들과 디스크를 사용하기위해 경합을 하지 말아야함
- 하나의 서버에 멀티 코어를 사용한다면 코어당 디스크를 분리해야서 사용하는걸 권장
- SSD권장
- 시스템 관리자와 RAID 관련해서 토론해보자
- OS에서 파일 시스템 캐쉬를 위해 사용할 충분한 메모리 양을 남겨 두는것도 DISK I/O만큼이나 성능에 영향을 줌
- Choosing a directive implementation
solrconfig.xml
<directoryFactory name="DirectoryFactory" class="${solr.directoryFactory:solr.NRTCachingDirectoryFactory}">
- StandardDirectoryFactory 는 디렉토리 클래스를 선택하는대 (OS가 64비트 & 오라클 JVM) 이면 MMapDirectory 이 제일 좋음
- 서버가 윈도우가 아니라면 NIOFSDirectory도 사용가능함
- solr/#/~cores/collection1에서 확인가능(우측 최 하단)
solrconfig.xml
<directoryFactory name="DirectoryFactory"
class="${solr.directoryFactory:solr.MMapDirectoryFactory}"/>
- 만약 64비트 쓰리즈를 사용한다면 위의 방식을 사용해서 명시적으로 설정도 가능
5.7.2 Segment merging
루센에서 세그먼트가 너무 많으면 성능에 좋지 않은 영향을 주기 때문에 필요하면 합쳐 줄수있다.
- shuld i optimize my index
옵티마이증을 하면 만약 32개의 세그먼트가 있었다면 지정된 값으로 세그먼트를 합함(기본은 1) 32개가 1개로 합쳐짐