7 Performing queries and handling results
지금까지 인덱싱관련해서 집중했는대 이제 쿼리관련된 사항을 알아보자
7.1 The anatomy of Solr request
쿼리는 search handler 에서 처리되며 서치 핸들러는 여러가지 컴포넌트를 호출해서 결과를 만든다.
- 7.1.1 Request handlers솔라에서 request handler는 요청을 처리하는 모든 핸들러를 의미한다. 여러 종류의 핸들러가 있으며 필요하다면 request hander base 를 implement 받아서 구현하면 된다.
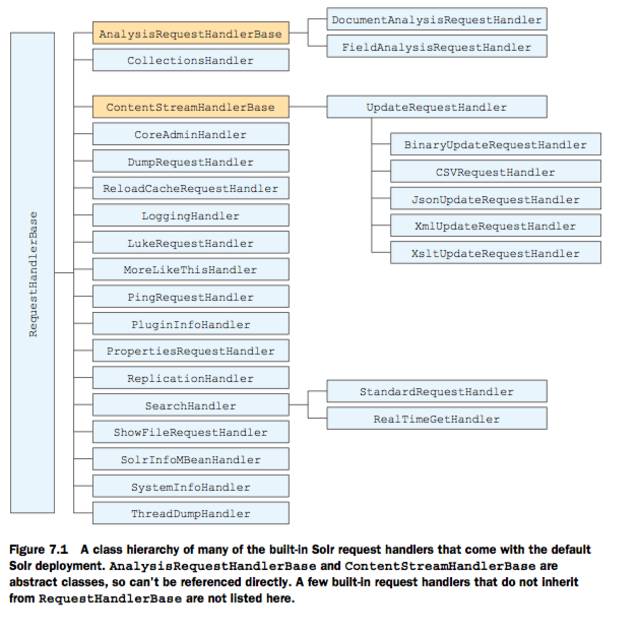
- DocumentAnalysisRequestHandler쿼리나 인덱스 등을 분석하기 위해서 updateRequestHandler 같은 여러 종류의 핸들어에서 스트림을 받아 실행 시키고(인덱스에는 더하지 않고)해당 결과를 보여준다.
- FieldAnalysisRequestHandlerDoucumentAnalysisRequestHandler 와 비슷하나 문서에 적용하는게 필드에 적용한다.
- UpdateRequestHandler문서를 받아 분석한후 인덱싱 한다. XML,JSON등 자료형에 따라 여러 종류의 구현채가 있다. 솔라에서 기본적으로 http header 의 contenttype 에 따라 구현체를 선택한다.
- CollectionHandler솔라 클라우드 컬랙션을 관리(ch13 참고)
- CoreAdminHandler하나의 솔라 인스턴스 안의 여러 인덱스 또는 코어를 관리하는대 사용(ch12 참고)
- DumpRequestHandler솔라에 보내진 문서를 확인 또는 디버깅 하기 위해 사용됨(대량으로 보낼때 정상적으로 처리 되고 있는지 확인 가능)
- ReloadCacheRequestHandler이핸들러는 FlatFileSourece 안에 위치하고 있다. externalFileField의 내용이 바뀔때 캐쉬를 재로딩하기 위해 사용된다. externalFileField는 솔라 인덱스에 저장되지 않고 솔라 밖에 파일로 저장되는 속성을 의미한다.
외부 필드 값이 변경되면 솔라에게 notification을 보내서 ReloadCacheRequestHandler를 통해 캐쉬를 재로딩해야한다. (ch 15 참고) - LoggingHandler로거와 로깅레벨 관련해서 참고하거나 조작 하기 위해 필요하다
- LukeRequestHandler솔라 인덱스에 대해 메타데이터 정보를 보기 위해서 사용한다. 예를 들어 어떤 필드가 이용되는가 인덱스에서 가장 자주 사용되는 단어는 무엇인가,단어는 인덱스 어떻게 분포 되어 있는가. 또한 문서 기분으로 정보 요청도 가능
- MoreLikeThisHandler텍스끼리 비슷한 문서를 추천하기 위해사용 보통 유저가 관심있어 하는 문서를 더 보여주기 위한 추천 시스템에서 사용 (ch16 참고)
- PingRequestHandler솔라 서버가 정상적으로서치 쿼리를 실행하고 (뒤는 옵션)솔라 서버에 건강체크파일이 존재한다면 OK 메시지를 리턴한다.보통 로드벨런스에서 솔라 서버가 살아있는지 확인할때 사용한다. 만약 건강체크 파일이 존재하고 쿼리를 실행 시킬수 있다면 서버는 건강하다고 할수있다 (ch12 참조)
- PropertiesRequestHandler모든 시스템 속성값을 리턴함
- ReplicationHandler클라이언트가 마스터의 솔라 인덱스를 복사해 가는대 사용함
- ShowFileRequestHandler컨피그 파일 세팅을 보기 위해서 사용됨
- SolrInfoMBeanHandlerJMX 사용하지않고 SolrMBean 오브젝트의 상태를 볼 수 있음
- SearchHandler검색을 하기 위해 기본적으로 사용하는 핸들러 이장에서 자세이 나옴
- SystemInfoHandlerJVM, OS등 특정 솔라의 특정 상태를 보기 위해서 사용
- ThreadDumpHandler자바 쓰레드 덤프를 보여준다.기본적으로 request 핸들러는 name 과 class가 필요하다.
name 이 /로 시작되면 리퀘스트를 url과 연결한다. class는 SolrRequestHandler interface를 구현했다.
startup=”lazy”로 되어 있으면 리퀘스트가 올때 핸들러를 만든다.
- 7.1.2 Search components유저는 하나의 리퀘스트를 보내지만 내부적으로 여러 스탭을 거쳐 리절트를 만든 후 리턴한다.
<searchComponent name="query" class="solr.QueryComponent" /> <searchComponent name="facet" class="solr.FacetComponent" /> <searchComponent name="mlt" class="solr.MoreLikeThisComponent" /> <searchComponent name="highlight" class="solr.HighlightComponent" /> <searchComponent name="stats" class="solr.StatsComponent" /> <searchComponent name="debug" class="solr.DebugComponent" /> 아래와 같이 사용 <requestHandler name="/select" class="solr.SearchHandler"> <arr name="components"> <str>query</str> <str>facet</str> <str>mlt</str> <str>highlight</str> <str>stats</str> <str>debug</str> </arr> </requestHandler>searchComponent를 정의 할때 name 과 class가 필요, 한번 정의 하면 여러 request handler 에서 호출해서 사용 할수 있음- defaults 없으면 request 파라미터를 채움 (있으면 request 파람 사용)
- invariants 무조건 사용(request에 동일한 파람있어도 무시)
searchComponent를 재 정의해서 default,invarinats 값등을 줄수 있다.<searchComponent name="query" class="solr.QueryComponent"> <lst name="invariants"> <str name="rows">25</str> <str name="df">content_field</str> </lst> <lst name="defaults"> <str name="q">*:*</str> <str name="indent">true</str> <str name="echoParams">explicit</str> </lst> </searchComponent><requestHandler name="/tvrh" class="solr.SearchHandler" startup="lazy"> <lst name="defaults"> <str name="df">text</str> <bool name="tv">true</bool> </lst> <arr name="last-components"> <str>tvComponent</str> </arr> </requestHandler>
- 7.1.3 Query parsers쿼리 파서는 검색 문법을 루센 쿼리로 바꿔서 문서를 바꾸는대 사용한다.
솔라는 여러 query parsers를 제공하고 확장해서 사용할수도 있다. 아래 그림은 rquest handler, serach compnents, query parser 에 대한 관계 표이다. request handler는 여러개의 search components 를 사용하고 serach component 는 여러개의 query parser 를 사용할수 있다.
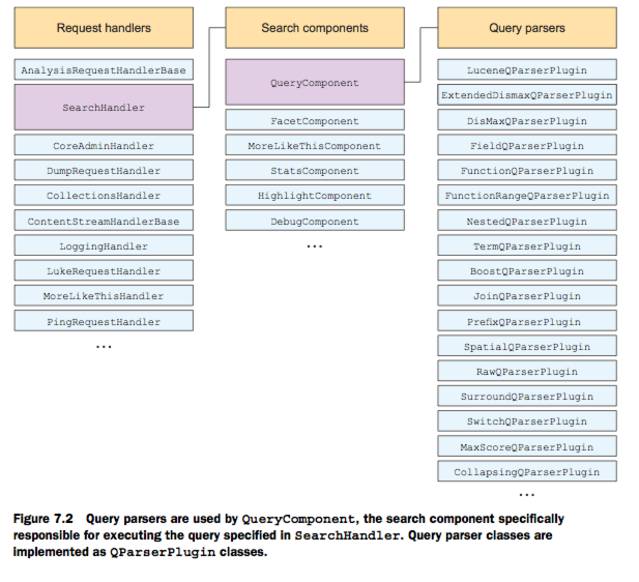
7.2 Working with query parsers
쿼리가 들어오면 QueryComponent 는 유저 쿼리를 (request의 q파라미터) query parser에 넘긴다. 기본적으로 솔라는 LuceneQParserPlugin 을 쓴다.
- 7.2.1 Specifying a query parser디폴트 쿼리파서를 requset에서 파라미터로 변경할수있다.
/select?defType=term&q= /select?defType=edismax&q=위처럼 변경하면 q 파라미터가 처리되는 파서가 변경됨으로 리턴 결과에 영향을 미칠수 있다./select?q={!edismax}hello world OR {!lucene}title:"my title"이렇게 쿼리 파라미터 안에서 쿼리 파서를 정할수 있으며 두개의 쿼리 파서를 사용 할수도 있다. - 7.2.2 Local params쿼리를 날릴때 특정 컨텍스트에서만 실행하고 싶으면 파라미터를 로컬로 처리해서 보낼수 있다. 이렇게 될경우 특정 쿼리 파서만 해당 파라미터를 사용한다.만약
로컬 파람이 없으면 모든 쿼리 파서가 해당 값을 사용해야 함으로 문제가 생길수 있다.- local params syntax
{! 로 시작해 }로 끝나고 키벨류 쌍으로 들어가고 스페이스로 분리한다.{!param1=value1 param2=value2 ...}
자 위의 두쿼리의 차이점은 무엇인가? 첫번째 꺼는 모든 파라미터가 글로벌로 적용된다. 아래는 hello world만 글로벌이고 나머지는 edismax의 파라미터로/select?q=hello world&defType=edismax&qf=title^10 text&q.op=AND /select?q={!defType=edismax qf="title^10 text" q.op=AND}hello world
만 사용한다.(두개 이상의 쿼리 파서를 사용할수 있다.)
- {!defType=edismax,{!edismax,{!type=edismax 3개다 의미는 똑같다 표현 방법만 조금씩 다르다.
- Parameter value
1. /select?q={!edismax qf="title^10 text" v="hello world"} 2. /select?q={!edismax qf="title^10 text"}"hello world" 3. /select?q={!edismax qf="title^10 text" v="\"hello world\""}위에 처럼 파라미터 벨류도 줄수있다.
1번의 경우 스페이스 등을 사용하기 위해 값을 “” 으로 묶었다.
2번을 보면 “”을 내부에서 사용하기 위해 이스케이프 문자를 사용했다
위와 같은 경우 쉽게 지저분할거라고 예상할수 있다. - Parameter defreferencing
/select?q={!edismax v=$userQuery}&userQuery="hello world"위와 같이 값에 키를 주고 뒤에서 키에 벨류를 맵핑해 높으면 솔라 내부에서 치완해서 사용한다.- 치환 안에서 치환 하는것도 가능하다.
- 한번 정의하고 여러곳에서 사용하는것도 가능하다.
- local params syntax
7.3 Queries and filters
쿼리 파서의 내부를 보기전에 우리는 유저 쿼리 그리고 필터가 어떻게 동작하는지 조금더 자세이 보자
솔라의 검색은 크게 두부분으로 구성되어 있다
- 쿼리에 맞는 문서를 찾는다.
- 특정 기준으로 정렬해서 상위 결과를 리턴한다.
- 특정 기준의 디펄트는 연관도이다.
즉 쿼리에 맞는 문서를 찾은 다음에 연관도를 계산하는 작업이 한번더 필요하다.
- 7.3.1 The fq and q parametersq는 query의 약자이고 fq는 filter query 의 약자이다 두개의 차이점을 보자
- Relevancy impact
- fq는 당신의 결과물을 매칭되는 문서로 제한한다.
- q는 1. 당신의 결과물을 매칭되는 문서로 제한한다. 2. relevancy 점수를 계산하기 위해서 사용하는 알고리즘의 (파라미터)단어들로 들어간다예를 들어보자 유저가 apache solr를 검색하면 q=apache solr , fq=technology 를 주면 좋다.
- Caching and execution speedfilter query 를 사용하는 이유는 두가지 목적이있다
- 필터쿼리는 보통 범용적인 검색 단어를 사용하기 때문에 캐쉬에 넣고 재사용하기가 쉽다.
- 검색 결과가 리턴 되려면 q를 사용해 relevany score를 계산하는대 fq가 있으면 한번더 필터링 해서 필요 없는 애들까지 스코어를 계산할 필요가 없다.
- Specifying multiple queryies and filters하나의 키워드만 가능하지만 fq 는 여러개를 붙일수 있다
//두개의 쿼리는 동일 결과를 리턴하다. q=keywords:solr&fq=category:technology &fq=year:2013 q=keywords:solr&fq=category:technologyANDyear:2013. - order of execution필터와 쿼리는 어떤 순서로 실행 될까?
1.fq 파라미터를 필터 캐쉬에서 찾는다 (인덱스에 있는 모든 문서에 대해 문서가 필터에 속하는지(1) 속하지 않는지(0)에 대한 비트들로 이루어진 문서셋) 2.만약 존재하지 않고 캐쉬가 on으로 설정되어 있다면 필터는 해당 필터(문서셋)셋을 쿼리해서 캐쉬한다. 3.모든 필터 셋에 대해서 교집합 연산을 취해서 한개의 문서 셋으로 줄인다. 4.q 파라미터가 종합된 한개의 필터셋과 같이 루센으로 넘어가 쿼리로 실행된다. 루센은 쿼리와 필터를 종합해 leapfrog라는 절차를 거친다(쿼리의 결과와 필터셋의 결과 양쪽에 i가 존재한다면 해당 id는 수집된다.) 이 절차에는 relevancy score 를매기는 작업도 포함된다. 5.만약 쿼리가 post filters를 가지고 있다면 query 와 필터의 교집합에 대해서 한번더 필터링을 한다.위의 설명을 생각하면 필터는 쿼리전에 실행되며 쿼리 실행 단계에서 필터는 같이 실행되며 (leapfrop step), post filter라는 특수한 필터는 쿼리와 필터의 교집합을 통과한 각각의 문서에 대하여 실행된다. 한 번더 요약해 보자1.필터가 필터 캐쉬에 있는지 찾는다 2.없다면 필터를 츶기 위해 인덱스에 쿼리를 한다. 3.모든 필터들을 합친다. 4.합친필터와 쿼리를 합쳐서 leapfrog step 을 처리한다. 5.post filters를 적용한다. 6.relevancy score를 꼐산하고 필요하면 솔팅 작업을 한 후 top n 결과를 클라이언트로 리턴한다.
- Relevancy impact
- 7.3.2 Handling expensive filters
필터가 마구 생긴다고 생각해보자 (예를 들어 로케이션별 거리에 대해) 수십만개의 필터가 생길수가있다. 해당 상황을 방지하기 하기 위해 필터에 룰을 정할수있다.- Turning off caching of filters쿼리에 특수한 문구를 써서 캐슁 되는걸 막을 수 있다.
fq={!cache=false}id:123& fq={!frange l=90 u=100 cache=false}scale(query({!v="content:(solr OR lucene)"}),0,100) - 첫번째 예제에서는 id는 캐쉬할 필요가 없다는걸 뜻함
- 두번째는 query({!v=”content:(solr OR lucene)”})를 찾아와서 0~100점 사이로 스케일링 하고(,0,100))
- lowest 90 ~ upper 100 점인 애들만 리턴 해라 라는 뜻이다.(frange l=90 u=100)
- 변수가 들어갔기 때문에 캐쉬 안함 (cache=false)
- changing the order of filter execution필터 자체의 계산이 오래 걸리는 애들일 경우 다른 필터에 비해 조금더 늦게 실행해서 속도를 향상 시킬수 있다.
fq={!cost=1}category:technology& fq={!cost=2}date:[NOW/DAY-1YEAR TO *]& fq={!geofilt pt=37.773,-122.419 sfield=location d=50 cost=3}& fq={!frange l=90 u=100 cache=false cost=100} scale(query({!v="content:(solr OR lucene)"}),0,100)점수가 낮을 수록 빨리 시작 된다. cost=1, cost=2를 실행하고 해당 결과에 비싼 cost=3결과를 적용한다.
(모든 인덱스의 문서에 관한 교집합 연산이기 때문에 위필터에서 0이라면 아래 필터에서는 계산할 필요가 없다.)
그 후 cost가 100 이상 일 경우 post filter라고 호칭하며 쿼리와 + 필터 교집합 연산이 끝난 다음에 제일 마지막으로 실행된다. - Post filtering실행 비용이 너무 비싸서 제일 마지막(최대한 적은 문서에) 적용하고 싶은 필터를 post filter 라고 부른다.
- 해당 문서에 대해서 collect가 호출되고 나서 다음 각 문서별로 실행된다.
- Turning off caching of filters
7.4 The default query parser(Lucene query parser)
LuceneQParserPlugin 은 모든 루센 문법과 솔라만의 문법까지 지원한다.
- 7.4.1 Lucene query parser syntax루센 쿼리 문법에 대해서 공부해보자, 만약 쿼리 문법이 틀린다면 솔라에서는 에러를 발생 시키고 해당 쿼리는 실패한다.
- Fielded term serachs솔라에서는 무조건 필드를 정해서 해당 인덱스에 쿼리를 해야 한다 만약 유저가 정하지 않는 다면 솔라 설정에서 정해 놓은 디폴트 값이 필드 값으로 정해져서 실행된다.
title:solr title:"apach solr" content:(serach engine) solr -> content:solr- 3번째가 필드를 정해 주지 않았을때 솔라에서 자동 치완해서 실행된다.
//필드는반드시 : 로 끝나야 한다. title:apache solr //위의 식은 아래 쿼리로 변경된다. title:apache content:solr - 여러개의 키워드를 찾아야 할 경우(grouped expression)
title:(apache solr) - 문장단위로 찾아야 할경우 (단어의 위치가 중요 phrase search)
title:"apache solr"
- 3번째가 필드를 정해 주지 않았을때 솔라에서 자동 치완해서 실행된다.
- Require Terms (AND)여러 키워드 쿼리를 할때 복수개의 단어가 모두 나와야 할때 아래와 같이 처리가능
apach AND solr apach && solr +apach +solr apach solr(만약 디펄트가 AND 연산자라면)위 4개는 모두 두개의 텀이 모두 존재하는 문서만 리턴한다. - Optional terms (OR)여러 키워드중 한개의 키워드만 존재해도 될때
apache OR solr apache || solr apache solr(만약 디펄트가 OR 연산자 라면)위 3개는 모두 동일한다. AND에 비해 당연이 비싸다. - phrase search문장을 인덱스 순서대로 검색할때 (단어의 순서는 보장하지만 스태밍 떄문에 정확하게 일치하지 않는 애들도 리턴가능)
"apache solr" "apache software foundation" - grouped expressions복잡한 쿼리를 처리하기 위해서 expression을 그룹핑 해서 줄수있다.
() parenthese 로 구분한다.//df=contents (apache AND (solr OR lucene)) AND title:(apache solr)contents에서 solr 또는 lucene 단어가 있으면서 아파치가 있고 title에 apache 와 solr가 둘다 존재하는애를 리턴해라 - Term proximityphrase query에서 단어간의 위치에 자유도를 줄수 있다.
"apache software foundation"~0 //아래와 매칭된다. "apache software foundation""apache software foundation"~2 //아래와 매칭된다. "apache software foundation" "software foundation apache" "apache foundation software" "apache [ohterWord1] [otherWord2] software foundation"즉 2개 숫자 만큼 포지션을 옴기거나 다른 단어가 들어와서 포지션이 변경되거 할수 있다
당연이 비싸디apach AND solr "apach solr"~1000000문서의 단어가 1000000 이내라고 할때 위의 두문장을 비슷한 결과를 리턴한다- 하지만 term proximity 가 더 비씨다.
- 그리고 term proximity 의 relevancy score 는 두 단어의 거리가 가까울 수록 더 가깞다.
- Character proximity문장검색 뿐만이 아니라 단어검색에서도 edit distance 로 검색하는게 가능하다 만약 리턴 결과가 없다면 유사한 단어를 검색해서 돌려줄수 있다.(유저의 오타나 어플리케이션의 종류에 따라)
solr~1 - Excluding Terms (NOT)특정 단어를 뺴는 연산도 가능하다.
solr -panel solr NOT panel solr AND NOT (panel OR electricity) - Range seraches가격에 따른 범위 검색이나 단어에 따른 범위 검색이 가능하다.
number:[12.5 TO 100] date:[2013-11-04T10:05:00Z TO NOW-1DAY] string:[ape TO apple] string:[ape TO apple]와일드 카드를 사용하는것도 가능하다.number:[* TO 0] number:[100 TO *] date:[NOW-1Year TO *] field:[* TO *]- {1 TO 10} 일경우 양쪽을 뺴고 2~9까지만
- [1 TO 10] 일 경우 둘다 끼고 1~10까지
- {1 TO 10] 일 경우 2~10까지
a location (latitude:[minTOmax]ANDlongitude:[minTOmax])
위와 같은 방법으로 솔라는 범위 검색쿼리를 한다.
- Wildcard seraches와일드 카드를 사용한 검색도 간으하다.
hel* w?rld, t??s is awe*m?하지만 사용하개 될 경우 솔라는 inverindex 에서 term을 찾는게 아니라 실제 인덱스에서 레인지 쿼리를 하기 때문에 엄청나게 느려 질수 있다. - Boosting expressions어떤 표현에 ^를 표시해서 점수를 계산할때 조금더 높게 줄수 있다.
(apache^10 solr^100 is^0 awesome^1.234) AND (apache lucene^2.5)^10 - Special character escaping아래는 예약어 임으로 \으로 이스케이프 해주어야 한다.
+ - && || ! ( ) { } [ ] ^ " ~ \* ? : /유저가 만약 특수문자를 던지면 어떻게 될까? 솔라에서는 에러가난다 그래서 우리는 아래 소개하는 파서를 사용한다.
(앞에서 특수문자 전처리 해줌)
7.5 Handling user queries(eDisMax query parser)
루센핸들러는 유저가 문자를 잘못 치면 에러가 발생된다. 그러므로 유저에게 직접 사용하게 할 수 없다. 또한 쿼리를 하나의 필드에만 할수 있다 만약 한개이상의 필드에서 처리할려면 설정에서 처리하던가 아래 처럼 연결해서 해야 한다.q=(title:some OR content:some) AND (title:keywords OR content:keywords)하지만 유저에게 해당 사항을 기대할수 없기 때문에 우리는 extened Disjunction Maximum query 파서를 사용한다.
- 7.5.1 eDisMax query parser overviewlucene query parser + disjuction max = eDisMax
- 7.5.2 eDisMax query parameters기본적으로 lucene query parser 는 syntax가 틀리면 에러를 발생하지만 eDisMax 은 lucene query parser 의 모든 syntax를 지원하면서 문법 에러가 발생 할경우 알아서 처리한다.
- 7.5.3 Searching across multiple fields멀티 필드에 대해서 검색할수 있다.
q=solr in action&qf=title description author필요하다면 아래와 같이 필드별로 부스팅 값을 주어 줄수 있다.q=solr in action&qf=title^1.5 description author^3
- 7.5.4 Boosting queries and phrases가깝다고 생각하는 단어들을 정의해서 점수를 boost 할수 있다. 메인 유저 쿼리와 분리되어 점수를 부스팅 할수있다.
- The PF(phrase fields), PF2, and PF3 Parametersq에 있는 애들을 주면 텀들간의 거리로 부스팅 한다. pf2, pf3도 비슷한기능이나 주어진 모든 텀이 아니라 단어별로 그램을 만든다
solr finds relevant documents //pf3 등 3개만 나오면됨 solr finds relevant finds relevant documents //pf2 등 2개만 나오면됨 solr finds relevant documents - The PS(PHRASE SLOP),PS2,PS3 parameterspf 파라미터를 사용할때 모든 텀이 정확한 위치를 고수 하지 않기를 바라랄 수도 있다. 있때 사용한다.
- the BQ(boost query) parameter검색 결과에서 툭정 필드의 값에 부스팅을 줄수 있다.
bq=date:[NOW/DAY-1YEAR TO NOW/DAY]오늘부터 작년까지 모든 문서에 대해서 부스팅 값을 줌 - the BF(Boost functions) parameter솔라가 지원하는 펑션을 부스팅에 사용하라고 할수 있다.
recip(rord(date),1,1000,1000)
- 7.5.5 Field aliasing필드에 별명을 짓고 유저가 해당 필드로 검색하게 할수 있다.
- f.{alias}.qf={realfield}폼을 사용
위의 쿼리는 q의 title이 title_t_en필드에 변경되어 검색하게된다./select?defType=edismax&q=title:"some title"&f.title.qf=title_t_en
아래와 같이 할 경우 가중치를 다루게 주어서 유저가 쉽게 검색하도록 도와줄수있다./select?defType=edismax& f.who.qf=personLastName^30 personFirstName^10& f.what.qf=itemName company^5& f.where.qf=city^10 state^20 country^35 postalCode^30& q=... //단순화한 내용 who:(trey grainger) what:(solr) where:(decatur, ga)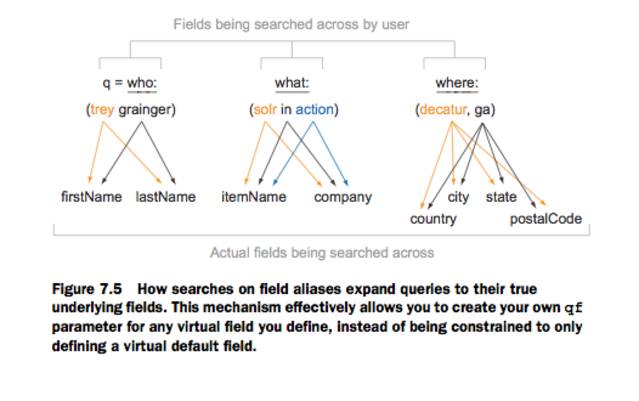
//실제 솔라에서 번역된 내용 (( (personFirstName:trey^10.0 | personLastName:trey^30.0) (personFirstName:grainger^10.0 | personLastName:grainger^30.0) )( (itemName:solr | company:solr^5.0) )( (state:decatur^20.0 | postalCode:decatur^30.0 | country:decatur^35.0 | city:decatur^10.0) )( (state:ga^20.0 | postalCode:ga^30.0 | country:ga^35.0 | city:ga^10.0) ))
- f.{alias}.qf={realfield}폼을 사용
- 7.5.6 User-accessible fields유저가 접근할 수 있는 필드를 제한 할수있다. 하지만 제한 자체를 쿼리 파라미터로 넘기면 대체.. 무슨 소용인가?
select?defType=edismax& &df=text& f.who.qf=lastName^30 firstName^10& f.what.qf=itemName companyName^5& uf=who what& q=+who:(timothy potter) +what:(solr in action) +"big data" - 7.5.7 Minimum matchand or 같은 문법은 어려움으로 조금 간단하게(….과연?) 새로운 매칭 문법을 도입해 보자
아래에서 +Integer는 몇개의 표현이 맞아야 하는가 -Integer 몇개의 표현까지 무시 할수 있는가?
+Percentage 몇퍼센트가 일치해야 하는가?, -Percentage 몇 퍼센트까지 검색 결과에 포함 안되도 되는가
등을 사용해서 검색한다.- positive integr | 2 | 최소 2개 이상의 표현은 맞아야함
- negative integer | -3 | 전부 일치 해야 하지만 3개 는 틀려도 됨
- positive percentage | 75% | 최초 75% 이상 일치해야함
- negative percentage | -30% | 전부 일치 해야 하지만 30%정도는 틀려도됨
- conditional percentage | 3<80% | 3개 이하라면 모든 애들이 일치 해야함 3개 이상이면 80이상 일치해야함
- multi | 3<-1 5<4 7<-30% | 3개이하 전부 매칭 4~5개는 4개는 매칭, 7개 이상은 전체의 -30%까지 일치 안해도됨
/select?q={!edismax mm="2<50% 4<-45%" v=$example}&example=... - example=solr | all terms must match
- example=solr is | all terms must match
- example=solr is a | 1 term must match (33% present, rounded up to 50%)
- example=solr is a search | 2 terms must match (50% present exactly)
- example=solr is a searcg engine |2 terms must match (40% missing, rounded up to 45%)
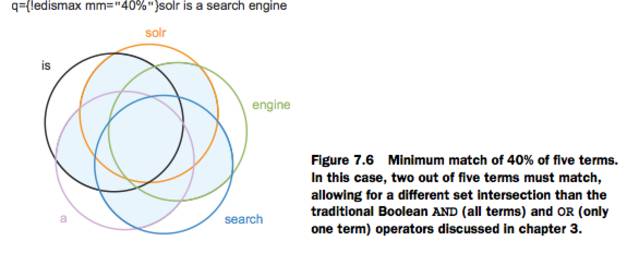
상세하게 조절해서 recall 과 precision둘다 올릴수 있음 조절하기전에 한번 더 이섹션 확인
- 7.5.8 eDisMax benefits and drawbacks
- 주의 : 여러 필드에 검색하는것 보다 하나의 필드로 여러 필드를 합쳐서 인덱싱한 후 검색하는게 더 빠름(하지만 이건 eDisMax 에서도 solr 내부에서 설정하면 동일하게 사용가능)
- 장점 : 세밀하게 컨트롤 가능하고, 유저 인풋이 잘못되면 알아서 수정
- 단점 : 루센핸들러의 경우 필드 별로 점수를 매기는게 가능하지만 eDisMax같은 경우 가장 높은 필드로만 점수를 매길수있다.(하지만 default에서만 그렇고 tie=1.0으로 하면 루센과 동일하게 필드점수를 합함)
7.6 Other userful query parsers
- 7.6.7 Spatial query parsers ch15 확인
- 7.6.8 join query parser ch15 확인
- 7.6.9 Switch query parser쿼리에 케이스문을 정해놓고 값에 따라 어떤 서치문장을 날릴지 결정 할 수 있다.
fq={!switch case.day='date:[NOW/DAY-1DAY TO *]' case.week='price:[NOW/DAY-7DAYS TO *]' case.month='date:[NOW/DAY-1MONTH TO *]' case.year='date:[NOW/DAY-1YEAR TO *]' case.else='*:*' v=$withinLast}
7.7 Returning results
검색되어 나온 서버 결과를 어떻게 서버에서 가공해서 클라이언트로 보낼 것인가?
- 7.7.1 Choosing a response format가능한 리턴값
- csv - json - php - phps - python - ruby - xml - xslt - javabin솔라에서 클라에 리턴 값을 주는게 아니라 서버에 리턴값을 준다. 라고 생각하자
필요하면 html 을 리스판스 라이터로 만들어서 돌려줄수 있지만 과연 솔라가 노출되는게 정상일까?/select?wt=xml&indent=true&q=*:*&fl=id,title&rows=2 //Response 2 <?xml version="1.0" encoding="UTF-8"?> <response> <lst name="responseHeader"> <int name="status">0</int> <int name="QTime">1</int> <lst name="params"> </lst> </lst> <result name="response" numFound="1000" start="0"> <doc> <str name="id">1</str> <str name="title">solr in action</str> </doc> <doc> <str name="id">2</str> <str name="title">lucene in action</str> </doc> </result> </response>//select?wt=json&indent=true&q=*:*&fl=id,title&rows=2 //Response 1 { "responseHeader":{ "status":0, "QTime":1, "params":{...}, "response":{"numFound":1000,"start":0,"docs":[ { "id":"1", "title":"solr in action", }, { "id":"2", "title":"lucene in action", }] }}//select?wt=csv&indent=true&q=*:*&fl,title=id&rows=2 //Response 3 id,title 1,solr in action 2,lucene in action - 7.7.2 Choosing field to return돌려줄 필드들은 저장되어야 한다 하지만 너무 많은 필드를 추가하면 속도가 느려진다.
- Returning stored fieldsrequest 파람에 fl을 준후 ,로 분리하면 해당 필드를 겸색 결과르 리턴한다.
/select?...&fl=id,name /select?...&fl=* - Returning dynamic values저장된 필드 뿐만 아니라 솔라에서 결과에 의해 생성되는 필드를도 리턴가능 (ex 연관 점수)
/select?...&fl=*,score - Document transformers샤드, 점수등 필요한 솔라 내부 정보도 요청해서 디버깅 용으로 사용가능하다.
select?...&fl=*,[explain],[shard]- [docid] | 루센 내부 문서 id
- [shard] | 샤드 서버 id
- [explain] | 연관 점수 관련 정보
- [explain style=nl|text|html] | 연관 점수 정보 표현 방법
- [value v=? t=int|double|float|date] | A specific value, the same for each document
org.apache.solr.response.transform .DocTransformer 을 확장해 커스터 마이징도 할수있다
- Return field aliases리턴되는 필드의 이름 overwrite 할수있다.
/select?...&fl=id,betterFieldName:actualFieldName
- 7.7.3 Paging through results솔라는 많은 문서에서 일치하는 쿼리의 문서를 찾은후 그중 소수의 문서(0~100)를 리턴하게 되어 있다 만약 많은 문서가 필요하면 페이징해서 리턴하자
``` /select?q=*:*&sort=id&fl=id&rows=0&start=5 ``` - rows=노출되는 로우수 - starts=페이지 시작수
7.8 Sorting results
솔라 검색 결과가 정렬되는 방법을 생각해 보자
- 7.8.1 Sorting by fields기본적으로 연관점수로 솔팅되고 동일한 연관 점수일 경우 루센내부 문서id 로 정렬된다.
sort=someField desc, someOtherField asc sort=score desc, date desc sort=date desc, popularity desc, score desc위 코드로 기본 정렬을 변경 할 수 있다.
schema.xml 정렬 되길 원한다면 indexed=true 되어 있어야 한다.- Sorting missing values키가 없는 값을 맨위로 또는 맨아래로 정렬 할 수 있다.
<fieldType name="string" class="solr.StrField" sortMissingLast="true" sortMissingFirst="false" /> - Sorting memeory footprint메모리를 많이 차지한다. 또한 당연이 처음 솔팅할 때 캐쉬 하기 때문에 맨 처음 쿼리는 느리다 솔팅을 해야 한다면 생각해 보자
- 7.8.2 Sortring by functions거리 기반 등 여러 펑션 기반으로 솔팅 할 수 도 있다.
- 7.8.3 Fuzzy sorting인덱스 스코어 정책에 따라 솔팅에 여러 문제가 생길 수 있다 ch 11, 15,16 을 확인하자
7.9 Debugging query results
- 7.9.1 Returning debug information아래와 같이 디버깅 펑션을 호출 할 수 있다.
/select?q=*:*&rows=3&debuq=true