6 Text analysis
6.1 Analyzing micro blog text
솔라가 어떻게 텍스트 분석에 접근하는 패턴을 확인하자
아래는 이번챕터에서 확인 할 컴포넌트 목록이다.
- analyzer, tokenizer and chain of token filters
- custom field type 정의 방법
- 일반적인 언어 분 전략 소개(remove stop words, lowercasing, removing accents, synonym expansion, and stemming)
아래의 트위터 메세지를 생각해보자 유저는 샌프란시스코 북쪽해변에서 라떼 카페를 먹고 있다 만약 다른 유저가 샌트란시스코 북쪽 해변에서 좋은 커피집을 검색한다고 가정해보자.검색엔진의 입장에서 우리는 유저의 검색어를 생각해 축약어 SF’S 를 san francico, sf 로 변경해야 하며 악센트를 없애야 하고 기본 적인 스탑 워드도 없애야 한다.#Yummm :) Drinking a latte at Caffé Grecco in SF's historic North Beach... Learning text analysis with #SolrInAction by @ManningBooks on my i-Pad위와 같은 텍스트가 솔라 텍스트 분석을 거치면 아래와 같이 변경된다. 어떤일이 벌어진걸까?#yumm,drink,caffe ,latte,grecco,sf,north,beach learn,text,analysis,#solrinaction,@manningbooks,my,ipad,i,pad아래는 기본적으로 솔라에서 제공하는 텍스트 분석 툴들이다.
- allterms -> lowercased(SF’s -> sf) | LowerCaseFilterFactory
- a,at,in…. -> 사라짐 | StopFilterFactory
- Drinking -> drink | KStemFilterFactory
- SF’s -> sf, san francisco | WordDelimiterFilterFactory
- Caffé -> caffe | ASCIIFoldingFilterFactory
- i-pad -> ipad, i pad | WordDelimiterFilterFactory
Yummm -> #yumm | PatternReplaceCharFilterFactory
우리는 이챕터에서 위의 필터들에 대해서 자세이 설명한 것이다.
6.2 Basic text analysis
책에서 준 설정으로 변경하고 예전 데이터 날리자cp $SOLR_IN_ACTION/example-docs/ch6/schema.xml $SOLR_INSTALL/example/solr/collection1/conf/ cp $SOLR_IN_ACTION/example-docs/ch6/wdfftypes.txt $SOLR_INSTALL/example/solr/collection1/conf/ rm -rf $SOLR_INSTALL/example/solr/collection1/data/*filedType을 정의해보자
- name : 전체적으로 나타낼 이름
- class : 어떤 타입을 다룰것인가.
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
- 6.2.1 Analyzer텍스트를 어떻게 분석할지 정한다 보통 1개이상의 analyzer 을 달며 보통 인덱스 시와 쿼리 시를 구분한다. 예를 들면 인덱스 시에는 동의어를 처리하지 않고(데이터가 커지므로) 쿼리할때 처리하면된다
단 만약 로우어 케이스를 인덱스시에 사용했다면 쿼리 시에도 빼먹지 말고 달아주자 - 6.2.2 Tokenizeranalyzer는 크게 3개로 스탭으로 텍스트를 분석한다.
- character filtering : 6.3.1 확인
- tokenization : 파싱
- token filtering : 필터링
토크나이저는 꼭 팩토리 패턴으로 만들어서 등록하자(생성자에 설정 넘겨주거나 xml에 설정 넘겨주는등에서 필요하다)
- 6.2.3 Token filter토큰에 대해 3개중 한가지 일을 처리한다.
- 변환 : 토큰을 변경시킴 예를 들면 lowercase or stemming
- 추가 : 동의어 등을 처리하기 위해 토큰을 추가함
- 삭제 : stop words등을 다루기 위해 토큰을 삭제함
- 6.2.4 StandardTokenizer기본 분리 조건
- 공백, 구두점(, :, 등)을 기준으로 단어를 분리하고 해당 공백과 구두점을 삭제
- 인터넷 도메인 이름과 이메일을 하나의 토큰으로 리턴
- 하이픈으로 연결된 단어를 2개의 단어로 분리(ex i-pad -> i, pad)
- 토큰 최대 길이를 지정(기본 255)
- 단어 앞의 #,@ 등을 삭제함
- 6.2.5 Removing stop words with stopFilterFactory언어에 따라 스탑 워드를 다르게 선택 할 수 있음 구글의 경우 인덱스는 다하고 쿼리가 올때 검색 결과에 따라 쿼리에서 스탑워드를 제거 하거나 안하거나를 판단해서 검색의 질을 높임
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_en.txt" /> - 6.2.6 LowerCaseFilterFactory—lowercase letters in terms로우어 케이스 처리를 안한 인덱스가 유저의 쿼리와 정확이 일치한다면 검색 결과의 질을 높일수 있다. 즉 늘 상대적이다. 또한 동의어를 처리할때 동의어가 로우어 케이스 기반으로 작성되어 있다면 로우어 케이스 필터 다음에 동의어 필터를 정의 해야 한다.
- 6.2.7 Testting your analysis with Solr’s analysis form문서를 솔라에 넣지 않고 분석테스트를 할수있음 어떻게 정의해 놓은 텍스 분석 스탭을 받는지 아주 친절하게 잘나온다.
아무런 작업을 하지 않고 한글을 테스트 해도 잘나온다
하지만 실제로 index 에 값을 넣고 query에 한글을 테스트 하면 잘 매치되지 않는다(매치되는 단어는 연파랑색으로 디스 플레이된다.)http://localhost:8983/solr/#/collection1/analysis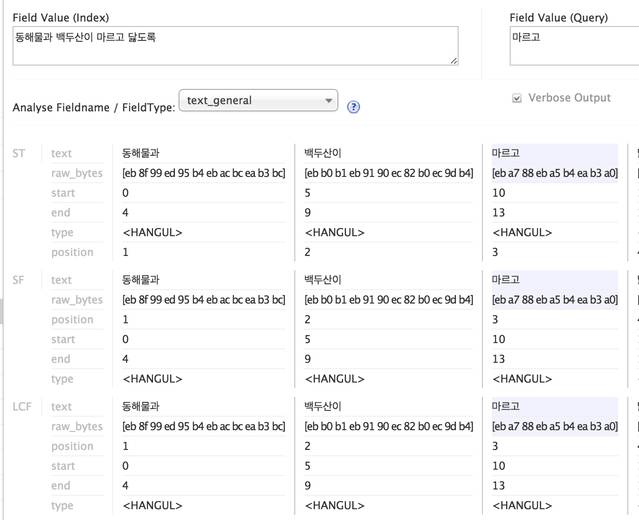
6.3 Defining a custom field type for microblog text
우리의 요구 조건에 맞추기 위해서 우리는 새로운 타입을 만들어 텍스트 분석을 해보자 요구 조건은 위와 같다
- Drinking -> drink | stemming
- learning -> learn | stemming
- SF’s -> sf, san francisco | remove ‘s
- Caffé -> caffe | remove diacritics
- i-pad -> ipad, i pad | remove hyphen in the middle of word
- #Yummm -> #yumm | collapse down to a max of two
- #solrinaction,@manningbooks -> solrinaction, manningbooks | remove #,@
<fieldType name="text_microblog" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<charFilter class="solr.PatternReplaceCharFilterFactory"
pattern="([a-zA-Z])\1+"
replacement="$1$1"/>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.WordDelimiterFilterFactory"
generateWordParts="1"
splitOnCaseChange="0"
splitOnNumerics="0"
stemEnglishPossessive="1"
preserveOriginal="0"
catenateWords="1"
generateNumberParts="1"
catenateNumbers="0"
catenateAll="0"
types="wdfftypes.txt"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true"
words="lang/stopwords_en.txt"
/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.ASCIIFoldingFilterFactory"/>
<filter class="solr.KStemFilterFactory"/>
</analyzer>
<analyzer type="query">
<charFilter class="solr.PatternReplaceCharFilterFactory"
pattern="([a-zA-Z])\1+"
replacement="$1$1"/>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.WordDelimiterFilterFactory"
splitOnCaseChange="0"
splitOnNumerics="0"
stemEnglishPossessive="1"
preserveOriginal="0"
generateWordParts="1"
catenateWords="1"
generateNumberParts="0"
catenateNumbers="0"
catenateAll="0"
types="wdfftypes.txt"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.ASCIIFoldingFilterFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true"
words="lang/stopwords_en.txt"
/>
<filter class="solr.SynonymFilterFactory"
synonyms="synonyms.txt"
ignoreCase="true"
expand="true"/>
<filter class="solr.KStemFilterFactory"/>
</analyzer>
</fieldType>
- 위와 같이 새로운 타입을 정의 하자 위의 설정 오버뷰
- PatternReplaceCharFilterFactory | 정규식을 사용해서 토크 나이징 전에 캐릭터를 변환한다.
- WhitespaceTokenizerFactory | 화이트 스페이스만 사용해 토큰을 분리한다.
- WordDelimiterFilterFactory | 알고리즘을 사용해 구두점 및 여러가지 방법으로 토큰을 분리한다.
- ASCIIFoldingFilterFactory | 악센트 등을 가능하면 ASCII문자로 변환시킨다.
- KStemFilterFactory | 영문에 stemming을 한다. | Porter stemmer 보다 조금들 aggressive 하다.
- SynonymFilterFactory | 쿼리와 동일한 동의어들을 집어 넣는다.
- 6.3.1 Collapsing repeated letters with PatternReplaceCharFilterFactory솔라에서는 캐릭터 필터라는 프리프로세서를 사용할수있다. 토큰 필터와 유사하게 해당 텍스트에 대해 더하거나 변경하거나 삭제하거나 할수 있다. 솔라4에는 4개의 charfilter 가 존재한다.
- solr.MappingCharFilterFactory | 외부 설정 파일에 설정된대로 특정 캐릭터를 변환한다.
- solr.PatternReplaceCharFilterFactory | 정규식을 사용해 캐릭터를 다른값으로 변경한다.
- solr.HTMLStripCharFilterFactory | 소스에 html 마크업 테그를 삭제 후 텍스트만 리턴
<charFilter class="solr.PatternReplaceCharFilterFactory" pattern="([a-zA-Z])\1+" replacement="$1$1"/>위의 필터는 정규식 필터이다 패턴은 반복대는 1나 이상의 문자를 1번 그룹으로($1) 두번 나열 해라 라는뜻이다.
정규식 테스트는 intellij 일 경우 cmd + f 로 테스트 하는게 최고 인거 같다 :)
- 6.3.2 Preserving hashtags, mentions, and hypenated termsStandardTokenizer 는 디펄트로 #,@,-을 단어에서 제거한다. 하지만 단어의 @를 제거 할 경우 대체적으로 서치 결과에 좋지 않는 영향을 미친다.(특히 스테밍과 합쳐지면)
또한 #fail 이라고 쓰면 일반 적인 fail의 의미가 아니라 다른 무언과의 관계에서 만족스럽지 못함을 의미한다.(첨알았다…) 만약 우리가 특수 캐릭터등을 보존하고 싶을때를 생각해보자
일단 StandardTokenizer는 어떻게 구현되어있을까? 만약 개발자리면 안에서 #,@등으로 그냥 split 하고 있음을 추측 할 수 있다 하지만 위 클래스는 상속하기 힘들게 되어 있다 그리고 우리는 코드 한줄 안적고 커스터 마이징 할 수 있다.- WhiteSpaceTokenerFactory그냥 화이트 캐릭터로만 분리하는애다 문제는 이렇게 하면 :),…등이 남는다.
- WordDelimiterFilterFactory
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" splitOnCaseChange="0" splitOnNumerics="0" stemEnglishPossessive="1" preserveOriginal="0" catenateWords="1" generateNumberParts="1" catenateNumbers="0" catenateAll="0" types="wdfftypes.txt"/>wdfftypes.txt에 우리가 분리자로 사용하지 않을 # => ALPHA, @ => ALPHA 로 정의 하면 해당 단어를 분리자로 사용하지 않는다. WordDelimiterFilterFactory 예제를 아래에 나열한다. - 사용하면 1로 표시한다 아래는 이름 | 설명 | 디폴트 값
- generateWordParts | 단어들을 내부 파싱규칙에 따라 분리하고 서브워드 그룹을 만든다. | 1
- splitOnCaseChange | 카멜 케이스를 분리함 SolrInAction -> Solr In Action | 1
- splitOnNumerics | 단어 + 숫자 들을 각각의로 분리 R2D2 -> R,2,D,2 | 1
- stemEnglishPossessive | 영문에서 소유표현을 없앰 SF`s -> SF | 1
- preserveOriginal | 원본을 토근으로 다시 넣음 SF
s -> SFS, SF | 0 - catenateWords | 서브워드 파트들을 하나의 단어로 연결한다. i-Pad -> iPad | 0
- generateNumberParts | 숫자용 구두점들을 분리한다. 865-1234 -> 865,1234 | 1
- catenatNumbers | 넘버가 서브 파트로 분리될 경우 다시 연결한다. 865-1234 -> 8651234 | 0
- catenateAll | generateWordParts = 1, generateNumberParts = 1 일때는 모든 부분을 하나의 토큰으로 연결한다 | 0
- 6.3.3 Removing diacitical marks using ASCIIFolingFilterFactory라틴 계열의 언어에서만 동작함으로 다른 언어의 악센트를 제거 할려면 ICUFoldingFilterFactory를 사용하자
영어에서 적용할려면 로우어 케이스 다음에 설정하는걸 추천한다.<filter class="solr.ASCIIFoldingFilterFactory"/> - 6.3.4 Stemming with KStemFilterFactoryKStemFilterFactory 머가 Porter 보다 훨씬 들 적극적으로(aggressive) 스태밍 작업을 한다.
내부적으로는 스태밍 해서는 안되는 단어집을 들고 있다 operating - 6.3.5 Injecting synonyms at query time with SynonymFilterFactory쿼리시에 동의어를 쿼리에 집어 넣는다. 인덱스 시에 집어넣으면 나중에 추가하면 예전 인덱스 된 애들이 문제가 생길수 있음으로 비추한다.
보통 맨마지막에 추가한다. (변형 될 필요가 없음으로)<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
6.4 Advanced field attributes
> 고급 옵션을 살펴보자
- schema.xml 의 고급 옵션
- 언어별 분석
- 솔라 플러그인을 활용해 텍스트 분석을 확장하기
- 6.4.1 Advanced field attributes아래의 옵션들은 text field에만 적용
- 속성 | true 일때 | default value
- omitNorms | 길이 nomailztion 을 끔, 인덱싱을 빠르게하고 저장공간을 절약함, norm을 키면 짧은 문장이 긴문장과 비슷한 관계 점수를 얻을수 있음 만약 필드의 길이가 비슷하다면 norm 을 끄는걸 권장함 | false
- termVectors | 단어 백터들을 사용해 코사인 디스턴스를 재는거 같은대 …성능에 문제 있을 여지있음 | false
- termPositions | 보통 hit highlihting 성능을 증가 시키기 위해 사용됨 인덱스 길이 큼|false
- termOffset | 보통 hit highlihting 성능을 증가 시키기 위해 사용됨 인덱스 길이 큼|false
- omitNorms검색할떄 TF공식 사용안함 (검색시 계산 비용 줄일수 있음)
- Terms vectors문서끼리 유사도 비교할때 사용 보통 (More like this)라고 부름 9장에 상세이 나옴
- 6.4.2 Per-language text analysis언어별로 는 어떻게 해야 할까?
- 가장 간단한 방법은 언어별 인덱스를 만드는거다
schema.xml <field name="text_fr" type="text_microblog_fr" indexed="true" stored="true" /> data <add> <doc> <field name="lang">fr</field> <field name="text_fr">Le vrai philosophe n'attend rien des hommes, et il leur fait tout le bien dont il est capable. Voltaire</field> </doc> </add>
- 가장 간단한 방법은 언어별 인덱스를 만드는거다
- 6.4.3 Extending text analysis using a Solr plugin이제 코드를 통해서 제공하지 않는 기능을 제공하는걸 확인해 보자 일단 aaa/dfg.com 이라는 짧은 url 이 있을때 해당 url을 원래 url로 변경해서 인덱스 하는 작업을 해보자 분석 체인 중 해당 기능은 토큰필터를 확장하는게 가장 편하기 때문에 확장해 보자 우리는 TokenFilterFactory와 TokenFilter 를 확장할것이다.
- Custom token filter class책의 소스를 확인하자
schema.xml <filter class="sia.ch6.ResolveUrlTokenFilterFactory" shortenedUrlPattern="http:\/\/bit.ly\/[\w\-]+" />플러그인을 만들었으면 jar 파일로 만들어 아래 설정대로 해야지 솔라에서 인식한다.<lib dir="plugins/" regex=".*\.jar" />플러그인 확장해서 소스 코드 짜고 jar파일 만들어서 플러그인에 넣고 스키마에 설정하고 솔라 올리면 된다.